ContextEval: Evaluating LLM Agent Context Policies for ML Experiment Design
Hikaru Isayama†,Adrian Apsay†,Julia Jung†,Narasimhan Raghavan†
† Equal contribution
Mentors: Ryan Lingo, Rajeev Chhajer
UC San Diego & 99P Labs / Honda Research Institute
Abstract
Large language models (LLMs) are increasingly deployed as autonomous agents in machine learning workflows. However, in most frameworks, the information provided to the agent—task descriptions, evaluation metrics, or prior optimization history—is treated as fixed. As a result, performance differences across systems often reflect differences in what agents are told rather than what they can reason.
We introduce ContextEval, a controlled evaluation framework that treats context visibility as a first-class experimental variable. By holding the model, environment, and prompt template fixed, we systematically vary four orthogonal axes of information exposure across four machine learning benchmarks to isolate the effects of context on optimization behavior.
Across our full factorial grid of 16 context policies, we find that optimization behavior is strongly initialization-dependent. The LLM acts primarily as a corrective heuristic—rapidly repairing poorly configured models but yielding diminishing returns near strong configurations. Furthermore, richer context such as semantic task descriptions and longer histories can encourage instability, while explicit parameter bounds improve structural constraint adherence without improving objective performance. These results motivate treating context visibility as a controlled experimental variable in all future LLM optimization benchmarks.
The Context Problem in LLM Agents
A central design element in agent-based systems is the context available to the agent. Prompts may include task descriptions, evaluation metrics, parameter constraints, or prior optimization history. However, in most frameworks, the structure of this informational exposure is not treated as a controlled experimental variable.
As a result, performance differences across agent systems may reflect differences in informational access rather than model capability, making it difficult to attribute observed results or reproduce findings. ContextEval solves this by treating context allocation as a first-class experimental variable, isolating the effects of informational exposure on optimization behavior.
Context-Trace Separation
To ensure behavioral effects trace solely to context exposure, ContextEval enforces a strict programmatic boundary: an execution Trace Layer logs the full environment state, while a policy-gated Context Layer filters the agent's observation space.
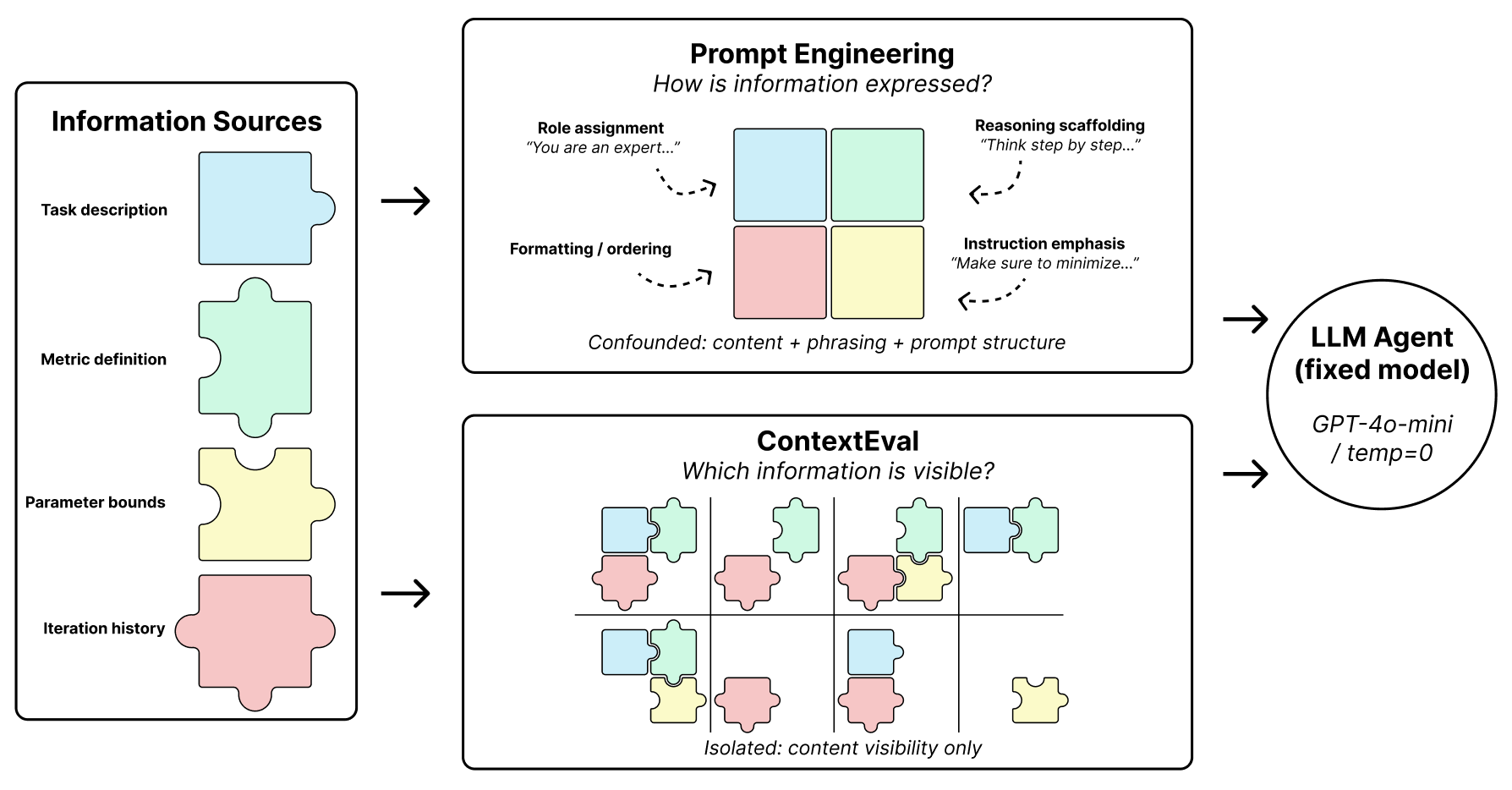
Systematic Context Variations
We vary four orthogonal axes of context visibility. Across these axes, we construct a full factorial grid of 16 context policies and evaluate agent behavior on four machine learning benchmarks: NOMAD materials regression, Forest Cover classification, California Housing regression, and Jigsaw toxicity classification.
1. Task Description
Exposure to semantic descriptions sourced verbatim from competition specifications.
2. Evaluation Metric
Visibility of the mathematical evaluation rule (e.g., RMSE, Mean AUC) without explicit directionality.
3. Parameter Bounds
Explicit definitions of the feasible region for the hyperparameter search space.
4. Feedback Depth
The temporal depth of historical feedback (e.g., observing only the last step vs. the last 5 steps).
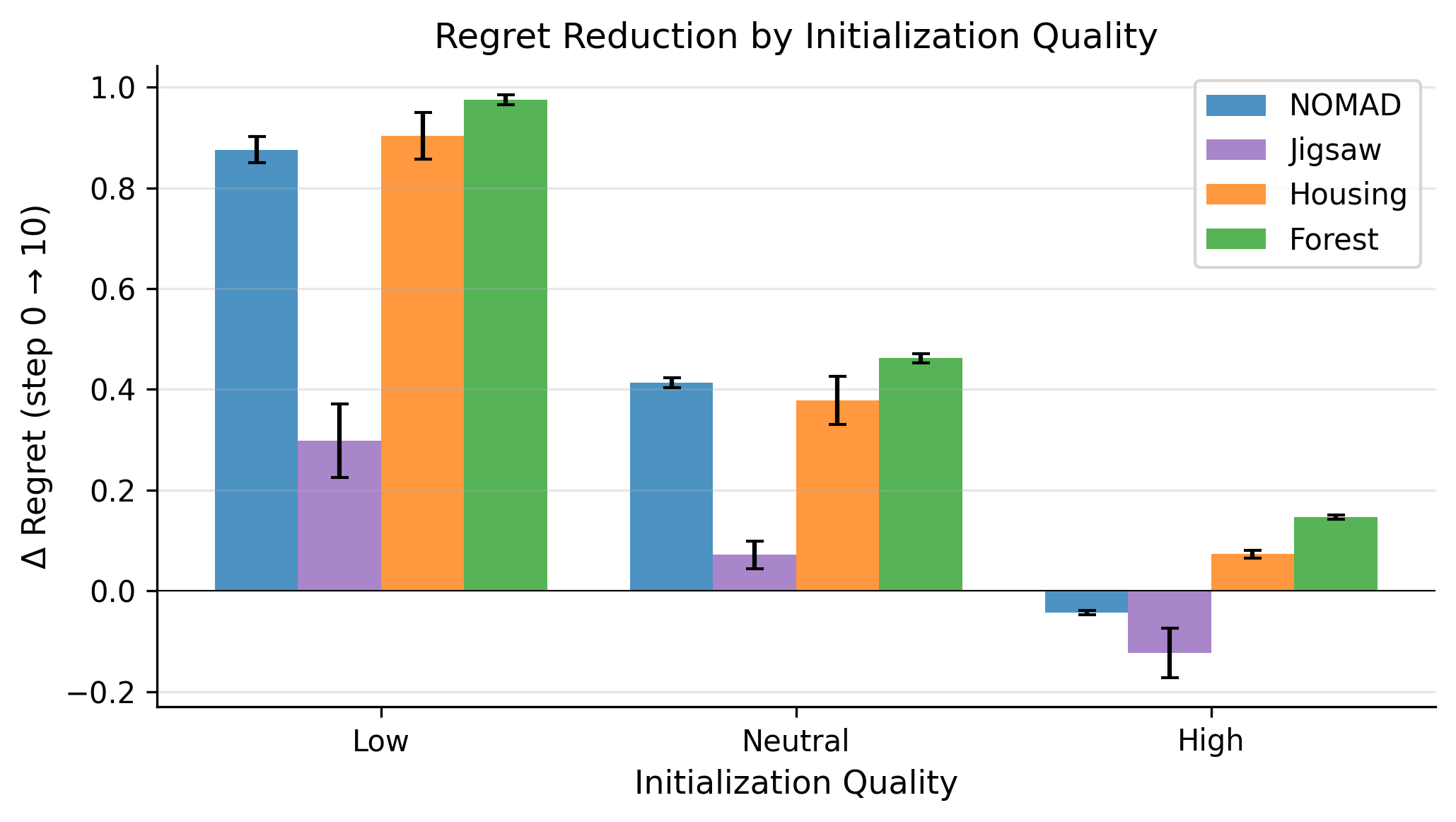
Stratified Initialization
To study how initialization quality interacts with context visibility, we evaluate a pool of 256 configurations using Sobol quasi-random sampling. We then partition configurations into three performance strata: High, Neutral, and Low. This ensures our evaluation covers the entire difficulty distribution of the search space.
Key Findings
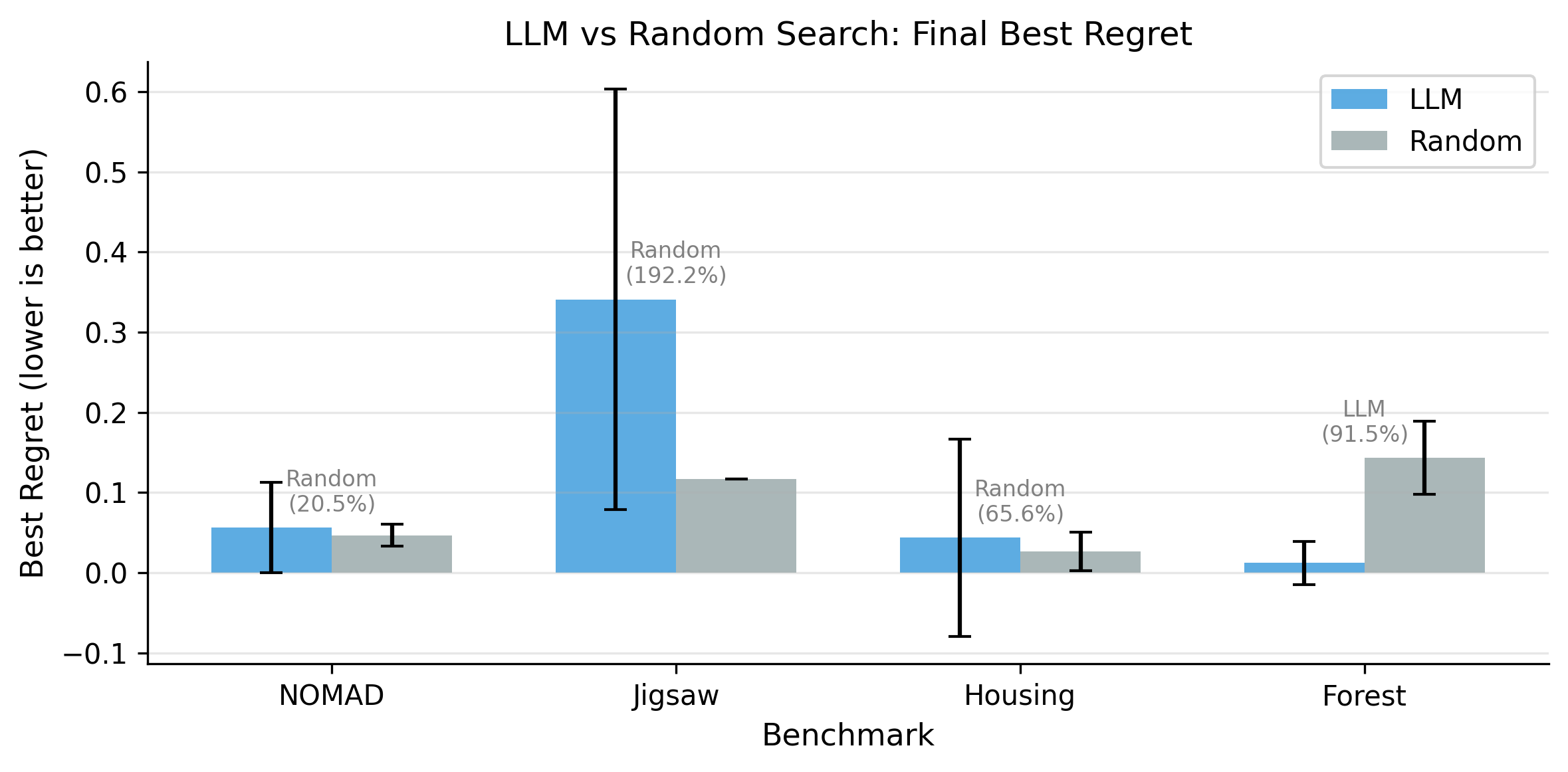
1. LLMs Act as Corrective Heuristics
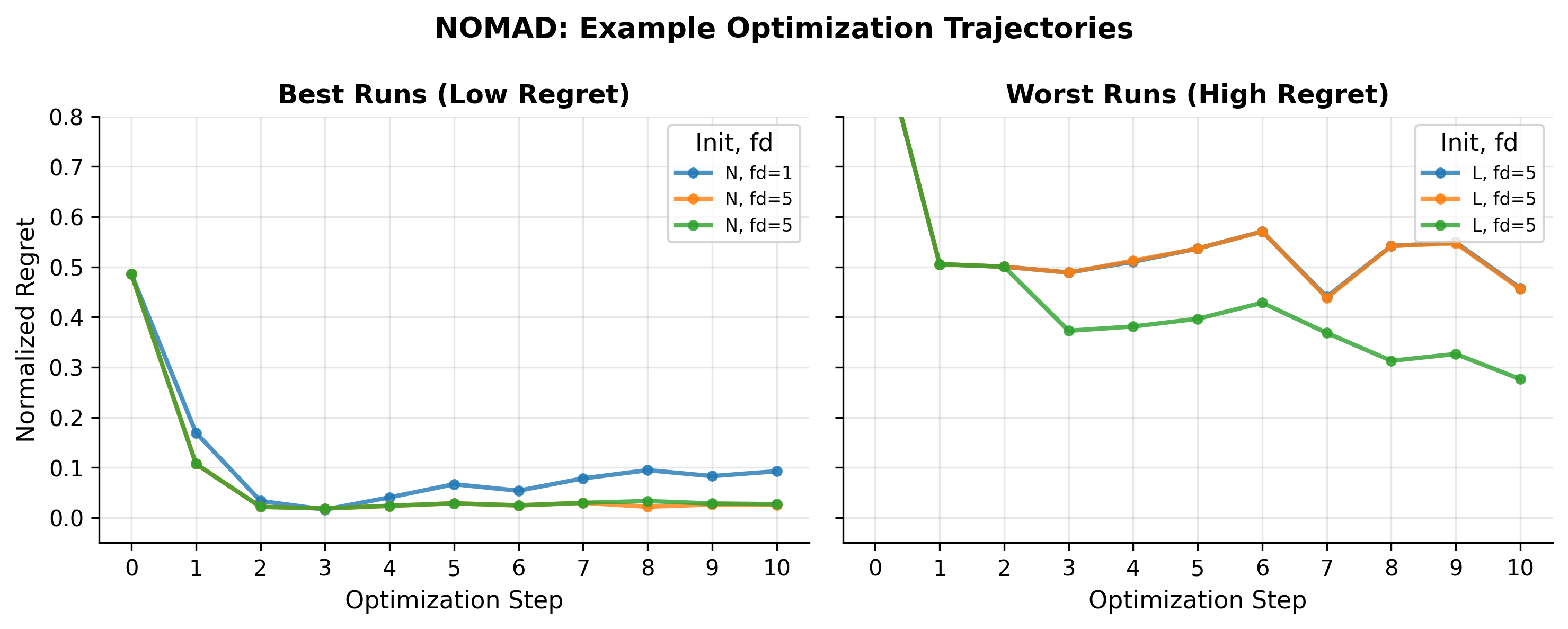
Optimization trajectories are heavily initialization-dependent. LLM agents rapidly escape poor configurations but provide diminishing returns near strong start points. Rather than acting as deep structural searchers, they behave mostly as corrective heuristics that do not consistently outperform random search.
2. Feasibility vs. Optimization Quality
Exposing explicit parameter bounds to the agent reliably eliminates constraint violations ("objective-scale hallucinations"). However, this structural compliance does not translate into improved final objective scores, highlighting a stark separation between feasibility restrictions and optimization capability.
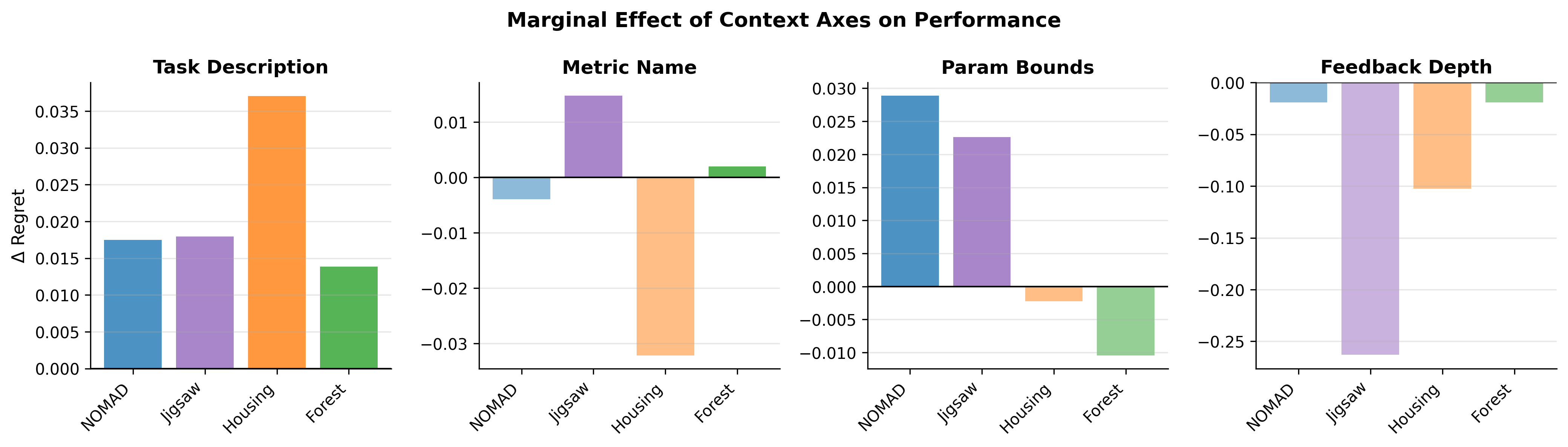
3. Context Rot & The "Lost in the Middle" Effect
Dense semantic task metadata introduces significant trajectory instability. When evaluating Kaggle tasks with lengthy descriptions, structural JSON instructions get "buried." This causes the LLM's attention mechanism to degrade, resulting in repeated parsing failures (Context Rot). Furthermore, deeper historical feedback frequently traps the agent in non-convergent oscillation when initialized from a poor state.
Conclusion
ContextEval demonstrates that an LLM's capacity to optimize machine learning experiments is deeply intertwined with the structure of the information it receives. While LLMs are effective debuggers, their limitations in maintaining stability under complex semantic noise suggest they currently operate best as corrective heuristics that do not consistently outperform random search, rather than autonomous black-box optimizers.
We argue that future evaluations of agentic frameworks must treat context visibility as a rigorously controlled experimental variable to accurately measure genuine reasoning capabilities versus prompt-based structural advantages.
📌 BibTeX Citation
If you find our project useful, please consider citing:
@misc{contexteval2025,
title={ContextEval: Evaluating LLM Agent Context Policies for ML Experiment Design},
author={Hikaru Isayama and Adrian Apsay and Julia Jung and Narasimhan Raghavan},
year={2025},
institution={UC San Diego},
note={UCSD DSC Capstone -- 99P Labs / HRI \& HDSI. Mentors: Ryan Lingo, Rajeev Chhajer}
}